基于关联规则挖掘的语料库文本分类

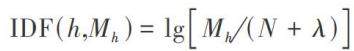
打开文本图片集
DOI:10.16652/j.issn.1004-373x.2026.10.026
引用格式:.基于关联规则挖掘的语料库文本分类[J].现代电子技术,2026,49(10):179-183.
中图分类号:TN911.2-34;TP183
文献标识码:A
文章编号:1004-373X(2026)10-0179-05
Corpus text classification based on association rule mining
Shao Yingruo
(Shanghai Jiao Tong University, Shanghai , China)
Abstract: In order to meet the demand for efficient processing of large-scale texts, discover the potential associated information in the texts and improve the accuracy of corpus text classification, a method of corpus text classification based on association rule mining is proposed. The TF-IDF algorithm is used to perform feature selection on the original corpus, so as to screen out high-value feature words and construct a feature word library. Apriori algorithm is used to mine the association patterns between feature words and text categories in thesaurus, and iterative strategy is used to mine frequent itemsets. Strong association rules are extracted according to the minimum support and confidence to construct the initial classification rule base. The CBA algorithm is introduced to prioritize and filter the rules in the rule library, forming the optimal classification rule set. The classification of corpus text is achieved by matching the feature item sets of the text to be classified with the rule antecedents. The experimental results show that the proposed method can realize precise classification of corpus text. For different types of texts, the Brier Score can be controlled below 0.25.
Keywords: corpus; text classification; feature selection; classification rule; CBA algorithm; association rule mining
0 引言
在数字化时代背景下,各类语料库迅猛增长,尤其是英语语料库,其作为跨语言交流、学术研究及语言教学的核心载体,涵盖新闻、医学、金融、学术等多种类型 [1-3] 。(剩余6451字)