融合多级语义的中文医疗短文本分类模型

打开文本图片集
中图分类号:TP391.1 文献标志码:A 文章编号:1671-6841(2026)01-0051-07
Abstract: To address the issues of insufficient extraction of key semantic information and decreased robustness in medical short text classification,a text clasification model that incorporated multi-level semantic information was proposed. Firstly,preliminary semantic features of the text were captured by using a pretrained model. Secondly,critical semantic information was extracted through a capsule network,ensuring that the model could effectively learn the core semantics of short texts. Attntion pooling techniques were applied to focus on document-level information,thereby enhancing the recognition and understanding of medical terminology and concepts.Finally,an adversarial training strategy was introduced to improve the stability and accuracy of the model when faced with ambiguous expressons or perturbed inputs.The effectiveness of the model was validated on three medical text clasification datasets,CHIPCTC,KUAKE_QIC and VSQ. The results showed that compared to the existing models, the F1 values of the proposed model increased on the three datasets,significantly enhancing the clasification performance of Chinese medical short texts.
Key Words: Chinese medical data; short text classification; semantic fusion; capsule network ;attention pooling
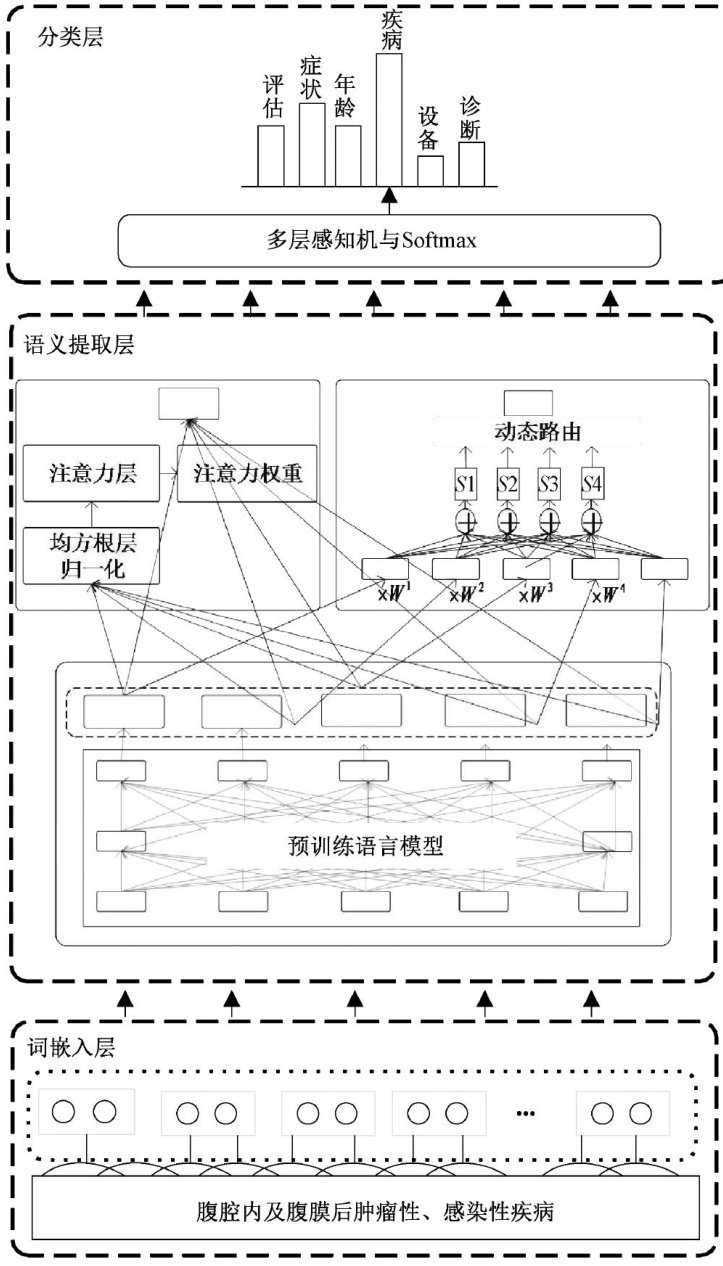
0 引言
传统的文本分类技术在处理中文医疗短文本时,难以准确捕捉医疗短文本中独特的词汇、语法和意图[]。(剩余11560字)
