基于EALMDA的医疗命名实体识别数据增强方法

打开文本图片集
关键词:数据增强;命名实体识别;自然语言处理;生成模型;Mixup
中图分类号:TP391.1 文献标志码:A 文章编号:1671-6841(2026)01-0043-08
DOI: 10.13705/j. issn.1671-6841.2024116
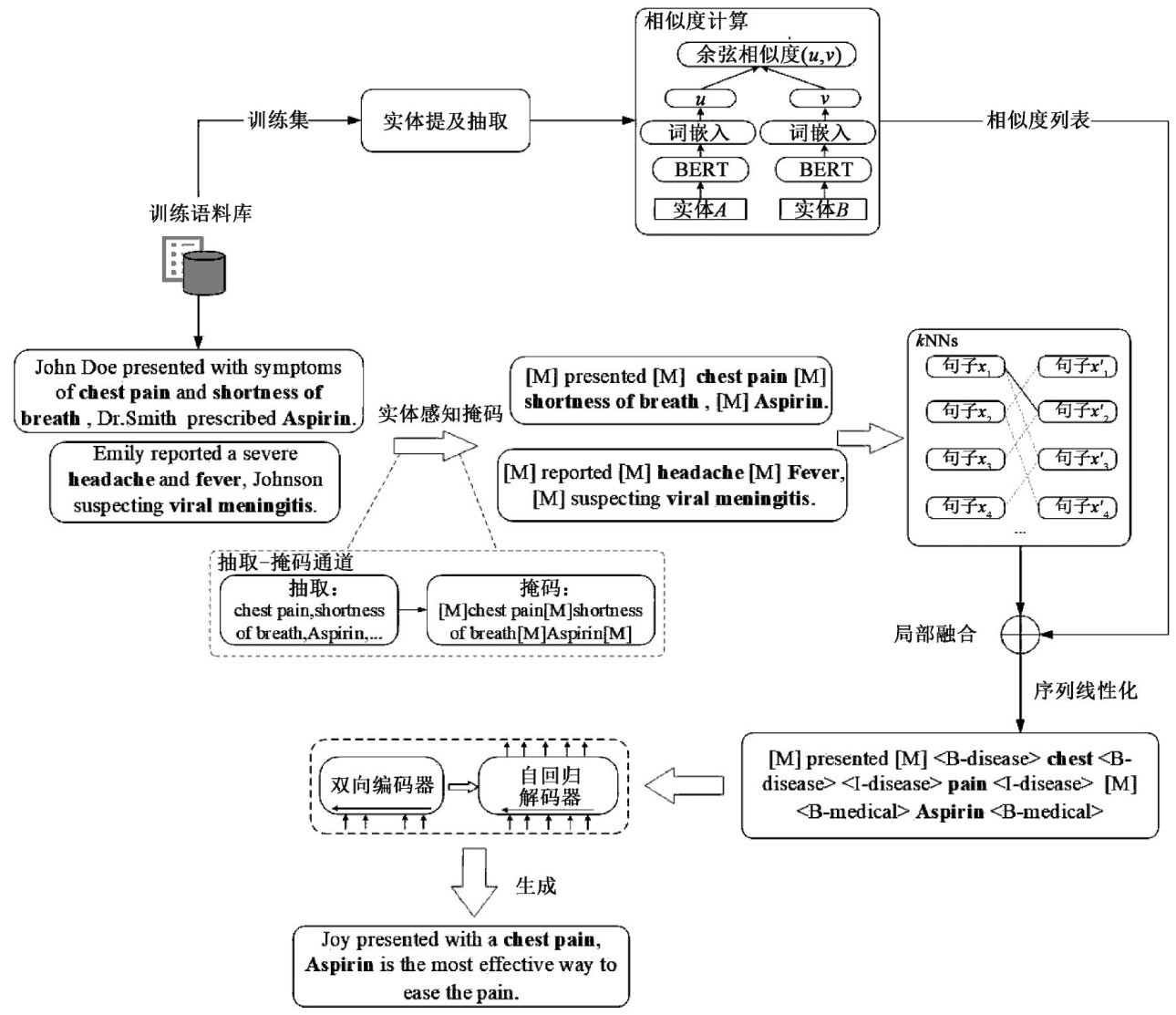
Abstract:Named entity recognition in the medical field involved identifying named entities from unstructured medical texts.This played a crucial role in various downstream tasks.Due to the complexity of medical named entities leveraging domain-specific knowledge was required in expert annotations,which led to a severe scarcity of annotated data in the medical field. To address this issue,an entity-aware mask local mixup data augmentation method (EALMDA) was proposed. This method firstly extracted key elements using an entity-aware masking channel and masked non-entity parts to retain core semantics. Then,masked sentences were fused through a linear combination of two sampling strategies: contextual entity similarity and k -nearest neighbors,which preserved the core semantics while increasing sample diversity.Finally,after sequence linearization,the sentences were input into a generative model to obtain augmented samples. Comparative experiments were conducted on five mainstream medical named entity recognition datasets, such as NCBI-disease, simulating low-resource scenarios against mainstream data augmentation baselines,and significant improvements were observed compared to baseline methods.
Key Words : data augmentation; named entity recognition; natural language processng; generative mod-el;Mixup
0 引言
近几年来,在医疗领域,命名实体识别(namedentityrecognition,NER)任务常用于从非结构化文本中识别和分类相关实体[1]。(剩余13234字)
